Single Points of Failure: Protecting Yourself from Hanging by a Thread

Many organizations are at risk of experiencing an outage due to the breakdown of a so-called single point of failure (SPOF), a resource that has no redundancy.
In today’s post, we’ll identify some of the more common SPOFs and explore how to classify and remediate them.
Related on MHA Consulting: Creating a Continuity Culture:
How Your Organization Can Make Business Continuity a Habit
Single Points of Failure in Brief
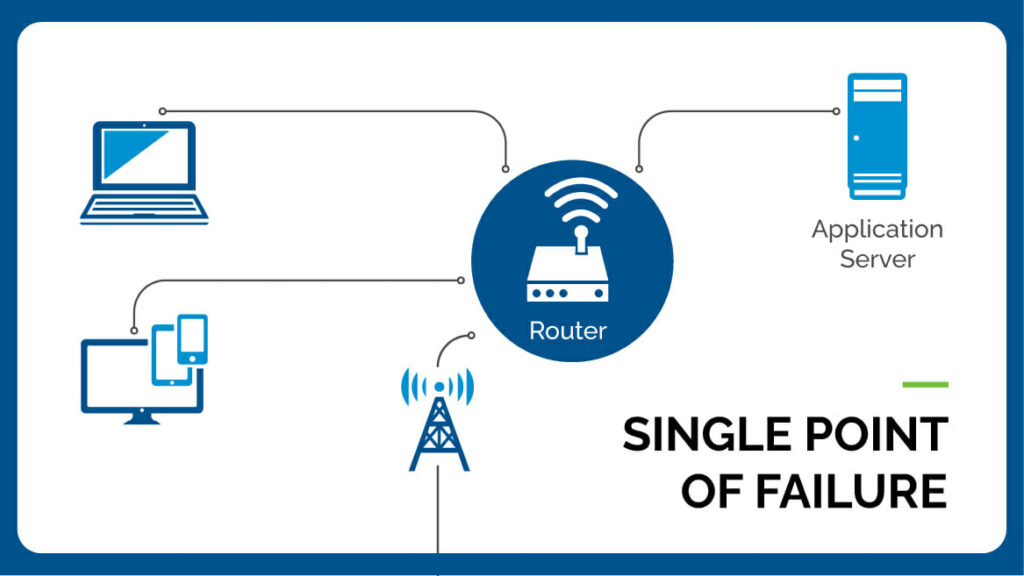
A single point of failure is a component or part of a system whose failure will cause the entire system to fail. It is a critical element that, if compromised, can lead to the breakdown of the entire system or process.
The failure of this single point can have cascading effects, disrupting the functionality and reliability of the entire system. The fate of any organization that has an SPOF in a critical business process is, in a very real sense, hanging by a thread.
Here are examples of common SPOFs:
- Single pieces of equipment, such as network devices or servers, that may impact one or more applications or processing functions
- Expensive pieces of equipment where only one is needed for processing, such as a custom stamping machine
- Manufacturing locations for specific products which cannot be made elsewhere
- An individual who is the only person capable of performing a critical process or possessing essential knowledge
- A single source vendor who is the only source of a critical service or product
Managing Your Organization’s SPOFs
Some SPOFs exist only because of an oversight and, once recognized, are easy to fix. Others might be well-known but are allowed to persist because remediating them would be prohibitively expensive.
Many people are familiar with the Serenity Prayer: “God grant me the serenity to accept the things I cannot change, courage to change the things I can, and the wisdom to know the difference.”
This is a good summary of the best approach for dealing with single points of failure.
Sometimes an organization has to accept the existence of the SPOF (if, for example, it’s too expensive to duplicate the resource).
Sometimes (though it might take courage and hard work) a company can make a change and eliminate the SPOF.
These challenges are relatively straightforward. It is being wise enough to know the difference between SPOFs that can and cannot be eliminated that is most likely to trip companies up, in my experience.
If there is a prevalent deficiency in organizations’ approach to managing SPOFs, it’s that they tend to be too quick to give up and decide to simply live with them. This is unfortunate because in many cases, there are steps that could be taken to reduce the company’s exposure. And even if the risk can’t be eliminated, it can often be reduced.
From an organizational perspective, the best approach to reducing vulnerability to SPOFs is a three-part processs involving identification, classification, and remediation.
Identifying SPOFs
The first thing to do in reducing the threat SPOFs pose to the organization’s ability to carry out its mission-critical processes is identifying them. Throughout the whole breadth of the organization’s activities, which are the components whose failure would cause the breakdown of the entire system?
Identifying SPOFs should be a component of both the Business Impact Analysis (BIA) and the Risk Assessment. In conducting those assessments, it’s important to be aware of the possibility that SPOFs and to be persistent in finding them. This can be challenging.
One of the reasons why is, sometimes people are aware of the SPOF but don’t want to reveal it because they fear its existence might reflect poorly on them or their department. For this reason, it is advisable, when looking for SPOFs, to keep the focus on improving resilience rather than pointing fingers.
Classifying SPOFs
Once an SPOF has been identifed, the next step is to classify it in terms of how easy it is to remediate. Each SPOF should be put it one of the following three categories:
- Can be remediated directly and easily, within a reasonable time and budget
- Cannot be remediated directly; however, a reliable workaround exists or could be developed
- Cannot be remediated, and there is nothing that can be done, within reason, to work around it
In addition, each SPOF should be categorized in terms of the probability of occurrence (low, medium, high) and the impact its failure would have on the organization (low, medium, high).
Remediating SPOFs
Once SPOFs have been identified and classified, the work of remediating them can begin. Here’s how to proceed with that part of the process:
If the SPOF can be eliminated, create a remediation plan and implement it based on priority. Typical remediation involves obtaining redundant equipment, creating and documenting workarounds, and training additional staff. Remediation might also require increasing the resiliency for certain applications and technologies. In some cases, remediating an SPOF might require the modification of processing or application setup to enable a process to self-heal or self-correct.
If the single point of failure cannot readily be eliminated, the organization will have to live with it. However, even here, there are often things that can be done to cushion the organization against the potential failure of the resource. Here are some examples:
- If the SPOF is a manufacturing facility making a specialized product, it might be possible to increase stock levels and identify and prepare a third-party vendor that could provide the item in the event of an emergency. The increased stock levels could cover the shortfall until this vendor is able to come on line.
- If the SPOF is an individual, and there is no one else at the organization with the necessary knowledge or skill set, and training or hiring someone to provide redundancy is not an option, then it might be possible to identify a third party who could take over in an emergency.
- If the SPOF is a self-managed data center with insufficient redundancy in environmentals such as power or cooling, and remediating the gaps does not make sense for some reason, then the organization might take any or all of the following steps: migrating the recovery of hypercritical applications to the cloud; creating a detailed listing of equipment and recovery procedures; utilizing a traditional recovery standby site to provide equipment, space, and power; and/or working with the business units to create a viable workaround for critical applications.
Enhancing Resilience by Addressing SPOFs
To avoid leaving its fate hanging be a thread, every organization should make a concerted effort to address its SPOFs. The best approach for managing SPOFs involves identifying, classifying, and remediating them.
Many SPOFs can be eliminated by obtaining redundant equipment or training staff. Even SPOFs that the organization is obliged to live with can often by mitigated by taking such steps as identifying outside resources that can be called on in an emergency.
Addressings its SPOFs is one of the best things any organization can do to fortify its operations and enhance its resilience.
Getting Help with Your SPOFs
Is your organization threatened by known single points of failure? Could unknown SPOFs lurk beneath the surface, posing a risk of unexpected interruptions to your critical operations? MHA consultants are highly experienced at identifying, eliminating, and mitigating SPOFs. Click here to schedule a time to talk with one of our consultants about how your organization can be made more resilient and its operations more robust.
Further Reading
- Every Single Day: Make Risk Management Part of Your Company’s Culture
- Creating a Continuity Culture: How Your Organization Can Make Business Continuity a Habit
- Learning the Local Culture: BCM Pros Need to Suit Their Programs to the Locality
- FFIEC: An Introduction to BCM’s Gold Standard
- All About BIAs: A Guide to MHA Consulting’s Best BIA Resources

Richard Long
Richard Long is one of MHA’s practice team leaders for Technology and Disaster Recovery related engagements. He has been responsible for the successful execution of MHA business continuity and disaster recovery engagements in industries such as Energy & Utilities, Government Services, Healthcare, Insurance, Risk Management, Travel & Entertainment, Consumer Products, and Education. Prior to joining MHA, Richard held Senior IT Director positions at PetSmart (NASDAQ: PETM) and Avnet, Inc. (NYSE: AVT) and has been a senior leader across all disciplines of IT. He has successfully led international and domestic disaster recovery, technology assessment, crisis management and risk mitigation engagements.







One thought on “Single Points of Failure: Protecting Yourself from Hanging by a Thread”
Comments are closed.